『形式意味論入門』を Haskell に書き下す (前編)
この記事は以下のページに移転しました.
一昨年のゴールデンウィークに池袋のジュンク堂を訪れた際,『形式意味論入門』という表題の本に目が止まり,数学や論理学を用いて自然言語表現の意味を形式的に考察する学問分野があることを知った*1.また,その道具立てとして単純型付きラムダ計算が用いられていることが,なおのこと私の興味を惹いた.ラムダ計算といえば,読者の多くが計算機科学分野での応用を思い浮かべると思うが,Richard Montague*2 が自然言語分野に応用して以来,そちらの方面でも道具立てとして用いられているようである.
")
この本は,Irene Heim と Angelika Kratzer による Semantics in Generative Grammar (以下 Heim and Kratzer) をベースに書かれているのだが,Heim and Kratzer で用いられる意味計算規則のうち,実質的に用いられるものはたった4つであるとし,前半で4つの意味計算規則の導入を行い,後半ではその他の自然言語現象に対して形式的な意味を与えていく,という構成になっている.また,統語論を学んだ人文科学系の学生を対象読者として書かれているため.序盤では集合論やラムダ計算に関する非形式的な説明に文量が割かれている.
この記事は,私が『形式意味論入門』の内容の習得を試みる際に,自分の理解が正しいかを確かめるため,Haskell のコードとして書き下した内容を下地に書かれている.言語表現及びそれらの外延をプログラム,とりわけ Haskell のプログラムにエンコードするメリットとしては,
- 意味計算を自力で行う必要がない
- 型の整合性が GHC の型検査機によって自動的に保証される
などが挙げられるだろう.
この記事は前後編に分かれている.前編では,事前知識の導入の後,4つの意味計算規則のうち最初の2つを導入する.後編では,更なる準備の後,残る2つの意味計算規則を導入する.
§1 文の「意味」
ここでいう「文」は平叙文のことだと思われる.たぶん元を辿ると "Satz" の訳なので,「命題」と訳してもよいのかもしれない.
合成意味論の祖である Gottlob Frege*3 によれば,文の意味 (de: Bedeutung, en: reference) は真理値 (de: Wahrheitswerth, en: truth value) である*4.形式意味論の分野では真理値は で表されることが多いようだが,混乱を避けるため本記事ではそれぞれ
と表記する.
形式意味論の研究はRichard Montague*5 をもって嚆矢とするが,彼の思想は Donald Davidson*6 が提唱した真理条件的意味論―すなわち,ある文の意味とは,その言語表現が真となるような状況であるとする―の流れを汲んでおり,これは現在でも形式意味論の標準的な立場となっている*7.しかし,計算機を用いてそのような条件を得ることは難しいため,本記事では Frege に倣い,文の意味は真理値であるという立場を取ることにする.
例として,
という文の意味を考えてみよう.この主張は伝統的に正しいとされている*8ので,この文の意味は真となるはずである.この事実を
と書く. は外延割当関数 (denotation assignment function) と呼ばれ,言語表現 (対象言語の項) をその意味に写す関数である.『形式意味論入門』によれば,「意味」とは
「自然言語表現」と「世界のあり方」の対応関係
として定義される*9.また,このような定義に基づき「記号と対応する実際の存在物・概念」という意味で「意味」を捉えるとき,「外延」と呼ぶ*10.以下この記事中では,「意味」と「外延」を区別せず用いる.
続いて,固有名詞 の意味
を考えてみよう.これはもちろん古代ギリシアはアテナイの哲学者
のことを指す.この事実を
と書く.左辺の外延割当関数の中にある がイタリック体になっていることに注意されたい.形式意味論では,言語を用いて言語を説明するという構造を取らざるを得ないため,説明の対象となる言語と,説明のために用いる言語とを区別しておく必要がある.これらをそれぞれ対象言語 (object language) とメタ言語 (meta language) と呼ぶ.また,混同を避けるため,対象言語はイタリック体で記述する.左辺の
は単なる対象言語内の記号であり,右辺の
は,実在する歴史上の人物としてのソクラテスである.また,地の文で書かれているものはメタ言語である.
ところで,principle of compositionality によれば, という文の意味は,その文中の語彙の意味
と,それらの組み合わせ方によって,またそれらによってのみ計算されるはずである.この語彙の組み合わせ方を意味計算規則と呼ぶ.
では,語彙と意味計算規則について見ていくことにしよう.
§1のまとめ
- 「意味」とは「自然言語表現」と「世界のあり方」の対応関係である.
- 文の意味は真理値である.
- 外延割当関数
は,言語表現をその意味に写す.
- 文の意味は,文中の語彙の意味と,それらの組み合わせ方 (意味計算規則) によって,またそれらによってのみ計算される.
§2 意味タイプ
例えば と
では,それぞれ固有名詞と形容詞であるから,それらの単語が属するカテゴリは異なることが予想される.ある単語が属する意味論上のカテゴリを意味タイプ (semantic type) と呼ぶ.混乱を生じない限り,この記事中では単に型と呼ぶ場合がある.
意味タイプは以下のように再帰的に定義される*11.ただし は個体を表す型,
は真理値を表す型,
は順序対である.
- a)
と
は意味タイプである.
- b)
および
が意味タイプならば,
も意味タイプである.
- c) 意味タイプは以上に限られる.
意味タイプを導入する目的は,項を類別することにある*12.2つの項が,外延割当関数で移した先で同じ集合に属するならば,それらの項は同じ型をもつようにしたい.型と集合は一対一に対応する.型 に対応する集合を
と書くことにすると,
となる.早い話,意味タイプとは,基底型 (ground type) とその上の関数型を考えたものである.読者に馴染み深い記法を用いた方が理解の助けになるであろうし,Haskell のソースコードとの対応が取れるため,この記事では
は
と表記することにする.また,この記事では,項
が型
を持つことを
と表記する.
『形式意味論入門』から読み取るのは難しかったのだが.おそらく,型は対象言語の項に付けられるものであって,メタ言語の項に付けられるものではない*13.したがって,
という記述は valid であり,「 という語は
型を持つ」という主張になるが,
という記述は invalid である (と思う)*14.また,
は valid な記述である.
§2のまとめ
- 対象言語の項を類別するため,項は型 (意味タイプ) をもつ.
- 意味タイプは,個体の型
からなる.
- 型
と書く.
- 特に
(個体全部の集合),
である.
- 特に
§3 様々な語彙とその意味タイプ
§1において,文の意味は真理値であることを見た.これはすなわち,文は 型を持つことを意味する.では,文以外の項はどのような型をもつのだろうか.
3.1  の外延
の外延
という語の意味,すなわち
は,前述の通り,古代ギリシアの哲学者であるソクラテスのことを指している.このように,固有名詞が与えられたとき,その外延は,
(個体全部の集合) の要素として一意に定まる.ゆえに,固有名詞は
型をもつ.
3.2  の外延
の外延
続いて という語彙の外延
を考えてみよう.ある個体
を与えられたとき,我々は
がリンゴであるかどうかを見分けることができる*15.ゆえに,
は
の部分集合で,リンゴであるような個体だけを集めてきた集合
と言える.
あるいは, の外延を次のように定義してもよい.
この関数 は,定義域を
として,引数
がリンゴであれば
を,そうでなれけば
を返す,いわゆる特性関数 (characteristic function) である.両者の定義間には自然な対応関係があるので,どちらを採用しても差し支えないが,Haskell で表現するに当たって特性関数の方が扱いやすいので,以後こちらの定義を用いることにする.また,
と簡単に表記する.
次に,自動詞 の外延
を考えてみよう.これも先程と同じように,すべての個体の中から,走っているもののみを選んできた部分集合
あるいは,走っている個体に対して を,それ以外に対して
を割り当てる特性関数
が の外延となる.また,
の場合と同様に,
とも表記する.
同様に,形容詞 の外延
は
である.
以上をまとめると,一般名詞・形容詞・自動詞の外延は から
への関数だと思ってよさそうである.同じことだが,対象言語のレイヤーでは,一般名詞・形容詞・自動詞は
型をもつ.
3.3  の外延
の外延
他動詞 の外延
を考えてみよう.
を用いた例文として
というものを考えてみる.
前節で自動詞 の意味を考える際,
という述語について,項
を探してきてはガチャガチャと当てはめてみて,
を真にするものとそうでないものに分類したのだった.同じように
の意味を考えてみると,
という命題に対し,
を探してきてはガチャガチャと当てはめてみて,
を真にする組とそうでない組に分類してみるとよさそうだ.ここで,
という組は
を真にする,といった具合である.
を,
を真にするような
の部分集合,つまり
上の二項関係*16と捉えると,
は以下のように定義できる.
ところが,自然言語表現においては, のような順序対を一語で表す機能は一般的ではなく,自然言語の構造に乗せるためには,2つの要素を1つずつ別々に渡せる方が便利である.そこで,
なる関数を
なる関数に対応付ける Schönfinkelization *17 という操作を施す*18.結局の所
という型を持つことになる*19.
また,ラムダ抽象の形で書くと以下のようになる.
ここで ではないことに注意されたい.統語構造を考えてみれば明らかだが,
と先に併合するのは主語
ではなく目的語
の方である.
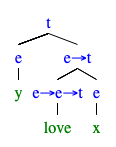
§3のまとめ
のような文は
のような一般名詞は
型をもつ.
のような自動詞は
のような形容詞は
型をもつ.
§4 モデル世界意味論
序盤で「意味」を,
「自然言語表現」と「世界のあり方」の対応関係
と定義した.しかし,この定義を愚直に採用すると,「世界」というものが曖昧である,大きすぎて取り扱いが難しい,などいった不都合が生じる*20.そこで,意味計算に差し障りのない範囲で,箱庭のような小さな世界を考えて,この箱庭世界のあり方と自然言語表現の対応関係を考える.この「箱庭のような小さな世界」をモデルと呼ぶ.
『形式意味論入門』では というモデルが想定されている.これは Charles Monroe Schulz の代表作である漫画作品『Peanuts』に由来する.以下この記事中では専ら
のみを考える.
には,以下の8つ (のみ) の個体が存在する.それぞれに対応する言語表現と合わせて示す.
また, という項が存在する.この語の外延は以下の通りである.
これ以外にも語彙は必要に応じて適宜導入する.
§4のまとめ
- 「世界」は取り扱いづらいので,「モデル」と呼ばれる小さな世界を考え,その中で意味計算を行う.
- この章以降では専ら
についてのみ考える.
§5 対象言語を Haskell に埋め込む
前置きが長くなったが,いよいよ意味計算を Haskell の上で行っていく.まず,準備として,対象言語を Haskell に埋め込んだ eDSL として Model 言語を導入する.
対象言語における意味タイプは,個体の型 と真理値の型
およびその上の関数型であった.
型と関数型を Haskell に落とし込むには,考えるモデルによらずそれぞれ
Bool と (->) を採用すればいいが, 型はモデルによって異なってくる.そこで,
型を表す型変数
entity を取るようにしておく.
| 対象言語 | Model 言語 |
|---|---|
entity (型変数) |
|
Bool |
|
| 関数型 | (->) |
{-# LANGUAGE GADTs #-} -- | 対象言語を Haskell に埋め込んだ eDSL data Model entity a where Entity :: entity -> Model entity entity -- ^ e 型の値 (個体) に相当 TruthValue :: Bool -> Model entity Bool -- ^ t 型の値 (文) に相当 Function :: (a -> b) -> Model entity (a -> b) -- ^ a -> b 型の値に相当
また,
data PEANUTS = Snoopy | Woodstock | Charlie | Sally | Lucy | Linus | Patty | Schroeder deriving (Show)
と定義しておく.このようにして, を Haskell に埋め込んだ
Model PEANUTS 言語が得られる.ここで,対象言語内の記号 は
Entity Snoopy :: Model PEANUTS PEANUTS と表され,その外延 は
Snoopy :: PEANUTS と表される.
また,外延割当関数を以下のように与える*21.
eval :: Model entity a -> a eval (Entity e) = e eval (TruthValue t) = t eval (Function f) = f
eval を用いると, という関係は
eval (Entity Snoopy) = Snoopy と書ける.
4つの意味計算規則
『形式意味論入門』で挙げられている4つの計算規則は以下の通りである.
- Functional Application (FA)
- Predicate Modification (PM)
- Traces and Pronouns Rule (T&P)
- Predicate Abstraction (PA)
以降の章では,これらの意味計算規則に対応する Model 言語のコンストラクタを増やすことによって,文の表現力を豊かにしていくという構成を取る.
§5のまとめ.
- Haskell のコード中では
Model言語は対象言語 (を埋め込んだもの) である. - 外延として Haskell の「地の文」を割り当てる.
evalは外延割当関数であり,Model言語の項を Haskell の項に写す.
§6 Functional Application (FA)
先程, の意味を以下のように定義した.
これを Haskell に書き直すと以下のようになる.
boy :: Model PEANUTS (PEANUTS -> Bool) boy = Function \case Charlie -> True Linus -> True Schroeder -> True _ -> False
という文の意味計算をしたい.まず,この文は以下のような統語構造を持つ.
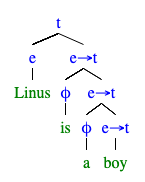
ここで と
は「語彙的に空虚」であると考える*22.すると,principle of compositionality に従えば,この文の意味
は―前述の通り真理値になるのだが―
及び
とその合成の仕方によって,またそれらによってのみ計算されるはずである.
実際のところ,どのような合成を行えばよいのだろうか.ここで第一の意味計算規則である Functional Application (FA) が導入される. であり,かつ
であるから,文の意味が真理値であったことを思い出すと,直観に従って,関数適用を施した
を意味としたいと思うのが人間の性である.
FA を形式的に書くと以下のようになる*23.
が branching node で,
を娘に持ち,
が
を定義域に含む関数であるとき,
である.
言い換えれば,次のようになる. が branching node であり,
および
を娘に持つとする.ここで
の意味は関数であり,どのような関数かというと,定義域に
を含んでいる.このとき,
の意味はどのように計算されるだろうか?その答えは,
の意味である項
に,
の意味たる関数
を適用した値
となる.
のような node を
Model 言語に追加してみよう.left-to-right な適用と right-to-left な適用の2種類が考えられる.
data Model entity a where -- ... FunApp_l2r :: Model entity (a -> b) -> Model entity a -> Model entity b FunApp_r2l :: Model entity a -> Model entity (a -> b) -> Model entity b
また,eval 関数を次のように拡張する.
eval :: Model entity a -> a -- ... eval (FunApp_l2r l r) = eval l $ eval r eval (FunApp_r2l l r) = eval l & eval r
と
は語彙的に空虚であるとしたので,以下のようなユーティリティ関数
is_a を用意しておこう.
is_a :: Model entity a -> Model entity (a -> b) -> Model entity b is_a = FunApp_r2l
さて,それでは実際に意味計算を行ってみよう.
main :: IO () main = hspec do describe "Linus is a boy." do let sentence = Entity Linus `is_a` boy it "is true" do eval sentence `shouldBe` True -- passes
同じように, の外延を計算してみる.統語構造は以下のような形である.
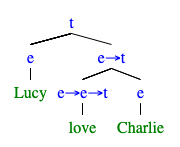
において
の意味を以下のように定義する.
love :: Model PEANUTS (PEANUTS -> PEANUTS -> Bool) love = Function $ \object subject -> case (subject, object) of (Lucy , Schroeder) -> True (Sally, Linus ) -> True (Patty, Charlie ) -> True _ -> False
この上で意味計算を行うと以下のようになる.
main :: IO () main = hspec do describe "Lucy loves Charlie." do let sentence = FunApp_r2l (Entity Lucy) (FunApp_l2r love (Entity Charlie)) it "is false" do eval sentence `shouldBe` False -- passes
§6のまとめ
- FA という意味計算規則が導入された.
§7 Predicate Modification (PM)
という文の意味を計算したい.統語構造は次のとおりである.
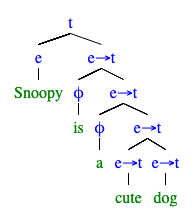
ここで, と
を娘にもつ node に注目したい.
であり,かつ
なので,FA では型が合わない.このような node の意味を計算するための規則として Predicate Modification (PM) を導入する*24.
かつ
であるとき,
である.
に関する2つの述語
と
が与えられたならば,それらの論理積を取った新しい述語
として取り扱おう,というアイディアである.
PM を Model 言語に追加してみよう
data Model entity a where -- ... PredicateModification :: Model entity (entity -> Bool) -- λx.P(x) -> Model entity (entity -> Bool) -- λx.Q(x) -> Model entity (entity -> Bool) -- α = λx.P(x)∧Q(x) eval :: Model entity a -> a -- ... eval (PredicateModification p q) = \x -> eval p x && eval q x -- | 'PredicateModification' を表すヘルパー関数 (/\) :: Model entity (entity -> Bool) -> Model entity (entity -> Bool) -> Model entity (entity -> Bool) (/\) = PredicateModification
PM と FA を用いて, の意味を計算すると,
,すなわち
となる.
において
と
の意味を次のように定義する.
cute :: Model PEANUTS (PEANUTS -> Bool) cute = Function \case Lucy -> True Patty -> True Sally -> True _ -> False dog :: Model PEANUTS (PEANUTS -> Bool) dog = Function \case Snoopy -> True _ -> False
この上で意味計算を行ってみよう.
main :: IO () main = do describe "Snoopy is a cute dog." do let sentence = Entity Snoopy `is_a` (cute /\ dog) it "is false" do eval sentence `shouldBe` False -- passes
Snoopy が cute であるかどうかについては議論が分かれるところだと思うが,少なくとも における
の定義に照らし合わせれば,
は偽ということになる.
§7のまとめ
- PM という意味計算規則が導入された.
後編に向けて
続く第3・第4の意味計算規則である "Traces and Pronouns Rule (T&P)" および "Predicate Abstraction (PA)" を取り扱うためには,variable assignment という概念を導入せねばならず,Model 言語を大きく拡張しなければならない.variable assignment は, のような,指標 (index) の付いた代名詞などを扱うための仕組みである.
という指標に対応する個体が何であるかは,文脈によって規定されるのだが,私にはこれは effect に見える.後編では,variable assignment を扱うための仕組みを用意したのち,残りの意味計算規則を見ていくこととしよう.
コード全文
#!/usr/bin/env stack -- stack --install-ghc runghc --package hspec {-# LANGUAGE BlockArguments #-} {-# LANGUAGE GADTs #-} {-# LANGUAGE LambdaCase #-} import Data.Function ((&)) import Test.Hspec (describe, hspec, it, shouldBe) -- | 対象言語を Haskell に埋め込んだ eDSL data Model entity a where Entity :: entity -> Model entity entity -- ^ e 型の値に相当 TruthValue :: Bool -> Model entity Bool -- ^ t 型の値 (文) に相当 Function :: (a -> b) -> Model entity (a -> b) -- ^ a -> b 型の値に相当 FunApp_l2r :: Model entity (a -> b) -> Model entity a -> Model entity b FunApp_r2l :: Model entity a -> Model entity (a -> b) -> Model entity b PredicateModification :: Model entity (entity -> Bool) -- ^ λx.P(x) -> Model entity (entity -> Bool) -- ^ λx.Q(x) -> Model entity (entity -> Bool) -- ^ λx.P(x)∧Q(x) -- | 外延割当関数 eval :: Model entity a -> a eval (Entity e) = e eval (TruthValue t) = t eval (Function f) = f eval (FunApp_l2r l r) = eval l $ eval r eval (FunApp_r2l l r) = eval l & eval r eval (PredicateModification p q) = \x -> eval p x && eval q x data PEANUTS = Snoopy | Woodstock | Charlie | Sally | Lucy | Linus | Patty | Schroeder deriving (Show) boy :: Model PEANUTS (PEANUTS -> Bool) boy = Function \case Charlie -> True Linus -> True Schroeder -> True _ -> False cute :: Model PEANUTS (PEANUTS -> Bool) cute = Function \case Lucy -> True Patty -> True Sally -> True _ -> False dog :: Model PEANUTS (PEANUTS -> Bool) dog = Function \case Snoopy -> True _ -> False is_a :: Model entity a -> Model entity (a -> b) -> Model entity b is_a = FunApp_r2l (/\) :: Model entity (entity -> Bool) -> Model entity (entity -> Bool) -> Model entity (entity -> Bool) (/\) = PredicateModification main :: IO () main = hspec do describe "Linus is a boy." do let sentence = Entity Linus `is_a` boy it "is true" do eval sentence `shouldBe` True -- passes describe "Lucy loves Charlie." do let sentence = FunApp_r2l (Entity Lucy) (FunApp_l2r love (Entity Charlie)) it "is false" do eval sentence `shouldBe` False -- passes describe "Snoopy is a cute dog." do let sentence = Entity Snoopy `is_a` (cute /\ dog) it "is false" do eval sentence `shouldBe` False -- passes
*1:ちなみに,意味論を研究する研究室に所属する友人に聞いたところ,形式意味論の入門に当たっては,Elements of Formal Semantics がおすすめだそうである.
*2:アメリカの数学者,哲学者.博士課程時代には Banach-Tarski のパラドクスで知られる Alfred Tarski の門下で公理的集合論を研究.その後,数理論理学を自然言語の意味論に応用する研究に着手し,今日の形式意味論の草分け的存在となった.
*3:ドイツの哲学者,論理学者,数学者.アリストテレス以来2,000年以上に渡って用いられていた論理学を再定義し,形式的な記号を用いて議論することを可能にした.今日の数理論理学の祖として知られる.
*4:ちなみに,文の意義 (de: Sinn, en: sense) は,その文が真ないし偽と規定される仕方である.
*5:アメリカ合衆国の数学者・哲学者.師であった Alfred Tarski より学んだモデル意味論を自然言語に適用し,形式意味論分野の草分け的存在となった.
*6:アメリカ合衆国の哲学者.彼の思想は哲学の多くの分野,とりわけ行為論,心の哲学,言語哲学に大きな影響を与えた.
*7:http://www.is.ocha.ac.jp/~bekki/project.html
*8:ソクラテスは人間であり,任意の人間は死ぬので (全称肯定判断).
*11:Heim and Kratzer §2.3
*12:と少なくとも私は読み取った.不文律として「ある項はちょうどひとつの型をもつ」というものがあると思うのだが,classification と捉えるとこれがうまくハマる.
*13:少なくとも Heim and Kratzer では厳密に区別されていない.
*14:前述の通り,型と集合は一対一に対応するため,そこまで厳密に区別する必要性も無いのかもしれないが.
*15:できると思ってほしい.
*16:Nicht: »Das komplexe Zeichen ›aRb‹ sagt, dass a in der Beziehung R zu b steht«, sondern: Dass »a« in einer gewissen Beziehung zu »b« steht, sagt, dass aRb. (Tractatus 3.1432)
*17:ロシアの論理学者・数学者である Moses Schönfinkel に由来する.
*18:我々が "currying" として知っている操作である.
*19: は右結合であると約束する.
*20:『形式意味論入門』p. 30 では,この定義のもとで の外延を考えるには,実際にこの世界中ですべての「学生」を知っていないと,この外延は定義できないことになる.と述べているが,この主張は怪しい気がしている.確かに,
を外延的定義によって与えることは難しいが,内包的定義によって与えることはできそうである.
*21:これは一見自明に見えるが,必ずしもそうではない.Heim and Kratzer §3.1 において,"If is a terminal node,
is specified in the lexicon." という規則が与えられている.
*22:この取り扱いが妥当なのかはちょっとわかっていない.導入部分では捨象していい程度の問題なのだろうか.
*23:Heim and Kratzer §3.1
*24:Heim and Kratzer §4.3.1